任务目标
Lab 1要求我们实现一个和MapReduce类似的算法。MapReduce 是一种用于大规模数据处理的编程模型,主要用于分布式系统中的并行计算。它最早由 Google 提出,旨在处理海量数据,尤其是在分布式系统中对数据进行分布式计算
用于测试的文件在src/main目录下,以pg-*.txt形式命名。我们的任务主要是统计出所有电子书中出现过的单词,以及它们的出现次数。但我们并不直接实现具体的统计词频的任务,而是实现MapReduce的通用框架,在框架里我们会加载外接链接库,获得具体的Map和Reduce方法。在框架里按接口调用Map和Reduce方法即可。根据Lab1的手册,外接链接库使用go build -buildmode=plugin ../mrapps/{plugin}.go命令编译出wc.so文件,在运行worker时需指定加载该链接库。mrapps目录下存放了多个用于测试的链接库源文件,我们自己写代码时简单调试用wc.so就足够了。
前置知识
文档资料
以下列出完成Lab 1所需要阅读的资料:
- Lab 1 2024文档 介绍了Lab1的任务和一些规范,同时给出了一些实现提示
- MIT 6.824 6.824的官方视频课程,完成Lab 1只需要看前两节甚至不需要看
- MapReduce论文 MapReduce论文,实现算法当然要参考算法原论文
- Go语言教程 对于有一定编程基础,要快速入门书写Go程序的。这本国内的教程足够,既涵盖了基本语法,也提供了一些常用标准库的API供随时查看
课程程序规范
Lab1主要关注如下文件
- mrapps/*
- mr/*
- main/mrsequential.go
- main/mrcoordinator.go
- main/mrworker.go
- main/test-mr.sh
- main/test-mr-many.sh
我们编写代码只需要修改 mr文件夹下的所有文件,可以自己增加额外的模块。调试时可以修改其他文件夹下的文件,但最好保证测试时还原被修改的文件,防止测试偏离原始意图
检查环境是否正确,我们可以先运行一个同步的MapReduce:
cd src/main
go build -buildmode=plugin ../mrapps/wc.go
go run mrsequential.go wc.so pg*.txt
在运行调试MapReduce程序时,我们可按如下步骤:
# 在任意窗口下
cd src/main
go build -buildmode=plugin ../mrapps/wc.go
# 在窗口1
go run mrmaster.go pg-*.txt
# 在窗口2,可多开几个窗口运行多个worker
go run mrworker.go wc.so
MapReduce算法
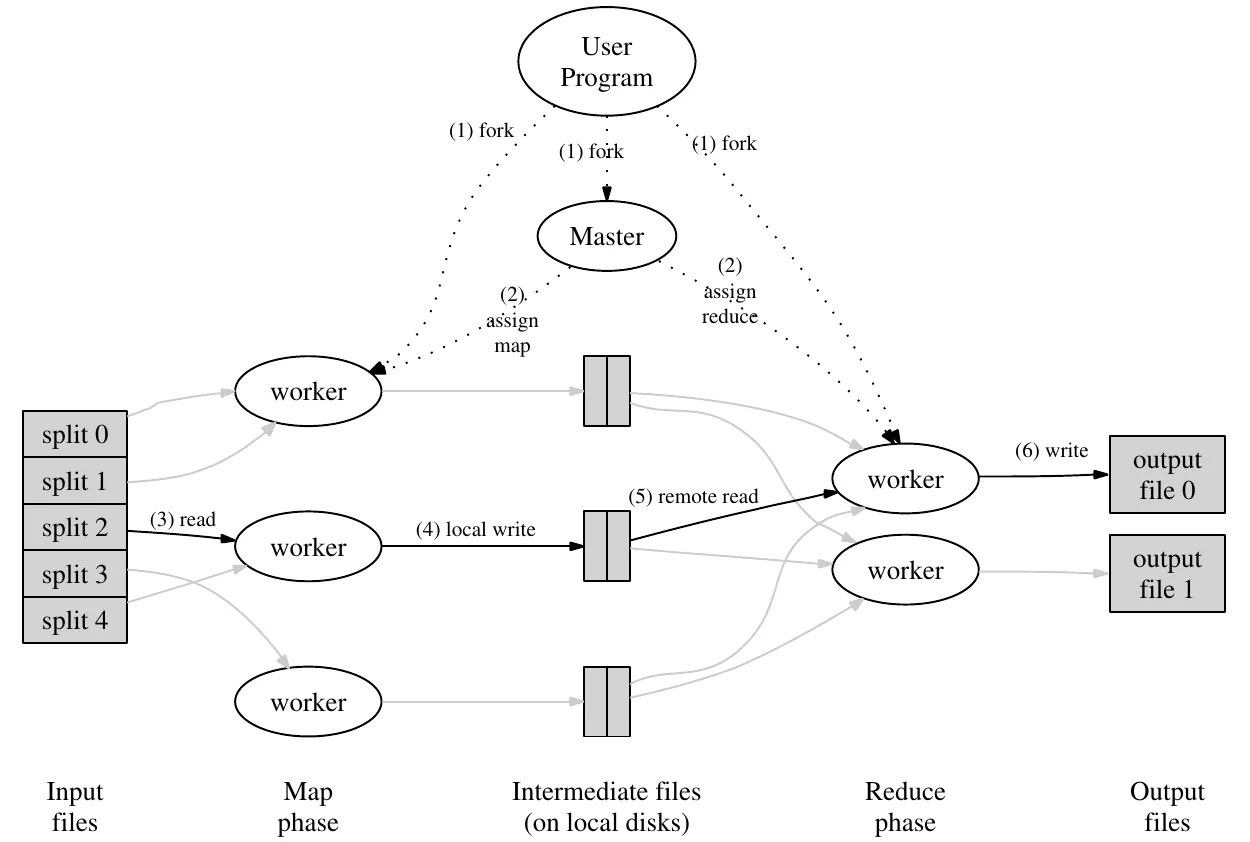
MapReduce算法的思想论文的section 3.1 Execution Overview讲的很清晰明了。这里再简单说明下
MapReduce主要有两个程序参与:
Master(在6.824中叫Coordinator)。负责管理整个MapReduce算法的运行情况;统筹各个Worker,为Worker分发Map或Reduce任务;和Worker之间通信,也可作为中间媒介传递Worker间的通信
Worker。每个Worker单独运行在一个机器或进程上,Worker是实际执行Map或Reduce的程序。一个Worker在同一时刻只能执行一个程序,要么是Map要么是Reduce,或者没任务处于等待状态。
算法逻辑
Map和Reduce函数接口可用Go表示为
func mapf(string, string) []KeyValue
func reducef(string, []string) string
- 创建1个Master和M个Worker。需要分配 M 个 Map 任务和 R 个 Reduce 任务(一般M是R的数倍)。主节点会选择空闲的Worker,并为其分配一个 Map 任务或 Reduce 任务。
- 被分配了 Map 任务的工作节点会读取相应输入片段的内容。它会将输入数据解析为
键值对(key/value pair),并将每个键值对传递给用户定义的 Map 函数。Map 函数生成的中间键值对列表(intermediate key/value pairs)会缓存在内存中 - 缓冲区中的
中间键值对列表(intermediate key/value pairs)会 定期 被写入本地磁盘,并通过partition函数将它们划分为 R 个区域(即和Reduce任务数量相同)。这些缓存在本地磁盘中的键值对的文件地址会被传回给Master,主节点负责将这些文件地址转发给 Reduce Worker - 当所有的Map任务都完成了,才可以开始Reduce任务
- 当 Reduce Worker从Master收到文件地址时,它读取文件获得中间键值对。之后Reduce Worker会根据中间键对数据进行排序,以确保相同的键被分组在一起。排序是必要的,因为通常有很多不同的键会映射到同一个 Reduce 任务,
Reduce函数接受特定的Key和该Key对应的所有intermediate key/value pair。如果中间数据太大,无法装入内存,则使用外部排序。 - Reduce Worker会遍历已排序的中间键值对列表,并将遇到的每个唯一中间Key和对应的中间键值列表传递给用户定义的 Reduce 函数。Reduce 函数的输出会附加到该 Reduce 分区的最终输出文件中。
- 当所有的Reduce任务完成了,当前MapReduce任务就结束了,产生的结果可以再传递给下一个MapReduce任务
注意事项
这里单独再强调算法中一些不容易注意或容易混淆的地方
- Map函数接受的 Key 和 Value 源自 Input数据(可以做一些预处理也可以不做),产生的 Intermediate Key 和 Intermediate Value由Map函数决定。
Reduce函数接受的Key 和 Values 源自 Intermediate Key 和 Intermediate Value 列表,函数的 Return值由Reduce函数决定。
以word count程序为例。Map接受的Key为文件名,Value为文件内容;产生的Intermediate Key是单词,Intermediate Value 是 “1”(标识该单词此处出现了1次)。Reduce接受一个Key/Value列表,Key/Value 与Map函数产生的Intermediate Key/Value;产生的Return是该单词的出现次数,即 接受的Key/Value列表长度(每个Key/Value都标识单词出现了1次,列表长度就是总出现次数) - Worker不断向Master申请任务,Master按情况让Worker执行Map或Reduce任务,或让它等待
- 只有所有Map任务都被分配并被执行完了,才可以分配Reduce任务
- Intermediate Key/Value列表可以写在Worker本地磁盘上,也可以写在云存储上。本实验所有程序都运行在一个机器上,故写在同一个磁盘上。
- Worker和Master通过协议进行通信,Worker之间通信需要通过Master协调。本实验中,Worker和Master使用RPC进行通信
实现思路
数据结构
Master
type Coordinator struct {
// Your definitions here.
idleMapTaskQueue *Deque[TaskInfo]
idleReduceTaskQueue *Deque[TaskInfo]
runningMapTaskMap map[int]TaskInfo
runningReduceTaskMap map[int]TaskInfo
completedMapTaskQueue *Deque[TaskInfo]
completedReduceTaskQueue *Deque[TaskInfo]
nReduce int
files []string
workerIdProvider WorkerIdProvider
cond *sync.Cond
}
Master需要存储每个任务的状态,这里使用了最通俗清晰的任务队列。将不同状态的任务分别放在单独的队列中。idle和completed状态的任务在加入和移除时一般不需要指定特定的任务,用数组方便地从队头队尾操作即可;running队列有时需要从队列中间移除特定的任务,用数组删除比较麻烦,这里用Map来存储,其实也可以理解为队列
我们需要为每个Worker提供一个唯一标识,设置了一个workerIdProvider,其实就是一个int 计数器和互斥锁的封装
nReduce和files由启动程序提供。nReduce和len(files)其实就是Reduce任务和Map任务的个数。cond是条件变量用来在操作Master的任务队列前加锁
TaskInfo
type TaskInfo struct {
workerId int
// map: file index reduce: reduce index
taskId int
createAt int64
}
workerId记录当前任务被分配给哪个Worker。taskId标识当前任务编号。
由于Master中不同状态、不同类型的任务都是分开保存的,这里可加也可不加 任务的类型和状态
Worker
type GeneralWorker struct {
id int
mapf func(string, string) []KeyValue
reducef func(string, []string) string
}
每个Worker有一个唯一标识。同时保存下mapf和reducef,方便调用
任务分配
Worker
不断向Master发送RPC获取任务。当Master完成Job后,Worker也可以结束了。RequestTask是一个RPC调用
// send RPC to the coordinator.
for {
var reply = worker.RequestTask()
if reply.JobDone {
break
} else if reply.TaskType == 0 {
worker.executeMap(reply)
} else if reply.TaskType == 1 {
worker.executeReduce(reply)
} else if reply.TaskType == 2 {
continue
} else if reply.TaskType == 3 {
break
}
}
type RequestTaskArgs struct {
WorkerId int
}
type RequestTaskReply struct {
// map: 0 reduce: 1 wait: 2 end:3
TaskType int
TaskId int
FileName string
WorkerId int
NReduce int
NFile int
JobDone bool
}
Master
首先检查是否有超时的Map Task。如果有则将该Task重新移入空闲队列。检查超时任务是为了对Stragglers任务进行容错,实现的是论文Section 3.6Backup Tasks。在本Lab中,任务10s未完成则超时
检查是否有idle的Map Task。如果有则分配
检查是否所有Map Task都已完成。如果不是,让Worker等待
对Reduce任务同样做上面三步。当所有Reduce Task均完成,则整个MapReduce作业完成
// Your code here -- RPC handlers for the worker to call.
func (c *Coordinator) HandleRequestTask(args *RequestTaskArgs, reply *RequestTaskReply) error {
// Your code here.
// check whether there are timeout tasks
// If so, mark the task as idle
// check whether there is idle task
// If so, assign map task
// check whether all map tasks done.
// If not, ask worker to wait
// check whether there are timeout tasks
// If so, mark the task as idle
// check whether there is idle task
// If so, assign reduce task
// check whether all reduce tasks done.
// If not, ask worker to wait
// all task done
return nil
}
Map/Reduce
Map
Map函数的逻辑比较简单,逻辑论文里讲的很清楚了,代码实现可以参考main/mrsequential.go
说明下我的实现的一些特点
- 我将intermediate按hash排序,避免频繁打开关闭文件
- 根据Lab 的Hint,Intermediate使用JSON格式存储在文件中
- 根据Lab 的Hint和论文的Section 3.3
Semantics in the Presence of Failures,Intermediate先写在一个临时文件,防止Map Worker中道崩殂。完成后再重命名临时文件 - 当Map任务完成后,需要向Master报告。同样是一个RPC调用
func (worker *GeneralWorker) executeMap(reply RequestTaskReply) {
// map task
// read file
// ...
// call mapf
var intermediate = worker.mapf(reply.FileName, string(content))
// write intermediate file
sort.Slice(intermediate, func(i, j int) bool {
return createReduceHash(intermediate[i].Key, reply.NReduce) < createReduceHash(intermediate[j].Key, reply.NReduce)
})
var i = 0
for i < len(intermediate) {
var j = i
for j < len(intermediate) && createReduceHash(intermediate[j].Key, reply.NReduce) == createReduceHash(intermediate[i].Key, reply.NReduce) {
j++
}
var tempMapFile, err = os.OpenFile(fmt.Sprintf("tmp-mr-%v-%v", reply.TaskId, createReduceHash(intermediate[i].Key, reply.NReduce)), os.O_APPEND|os.O_CREATE|os.O_WRONLY, 0644)
if err != nil {
log.Fatalf("cannot open %v", tempMapFile.Name())
}
var enc = json.NewEncoder(tempMapFile)
for k := i; k < j; k++ {
err = enc.Encode(&intermediate[k])
if err != nil {
log.Fatalf("cannot write %v", tempMapFile.Name())
}
}
var mapFileName = fmt.Sprintf("mr-%v-%v", reply.TaskId, createReduceHash(intermediate[i].Key, reply.NReduce))
err = os.Rename(tempMapFile.Name(), mapFileName)
if err != nil {
log.Fatalf("rename tempfile failed for %v", mapFileName)
}
i = j
}
// report to master
worker.reportTask(reply)
}
Reduce
Reduce的实现注意事项和Map类似。
func (worker *GeneralWorker) executeReduce(reply RequestTaskReply) {
// reduce task
var reduceFilesPattern = fmt.Sprintf("mr-*-%v", reply.TaskId)
var files, _ = filepath.Glob(reduceFilesPattern)
var intermediates = make([]KeyValue, 0)
// read intermediate files
// ....
// sort intermediates
sort.Sort(ByKey(intermediates))
var outputFileName = fmt.Sprintf("mr-out-%v", reply.TaskId)
var tempMapFile, err = os.OpenFile(fmt.Sprintf("tmp-%v", outputFileName), os.O_APPEND|os.O_CREATE|os.O_WRONLY, 0644)
if err != nil {
log.Fatalf("cannot open %v", tempMapFile.Name())
}
var i = 0
for i < len(intermediates) {
var j = i
for j < len(intermediates) && intermediates[j].Key == intermediates[i].Key {
j++
}
var values = make([]string, 0)
for k := i; k < j; k++ {
values = append(values, intermediates[k].Value)
}
var output = worker.reducef(intermediates[i].Key, values)
fmt.Fprintf(tempMapFile, "%v %v\n", intermediates[i].Key, output)
i = j
}
tempMapFile.Close()
os.Rename(tempMapFile.Name(), outputFileName)
worker.reportTask(reply)
}
Master.HandleReportTask
当Master收到某个任务完成或失败后,根据任务信息,对任务的完成状态进行调整即可。注意操作任务队列时需要加锁
可选的增强
合适的Partition Function
在Map函数中我们需要通过Partition函数将生成的 中间键值 放入nReduce个区域中的一个。一般用于划分的函数会使用Hash,此外我们可以按照任务本身固有的一些规律来设计Partition函数。例如输出的键是URL,那么就可以将HostName作为一个变量来决定Reduce区域的划分,这样可以保证相同的HostName被划入同一个Reduce区域。
顺序保证
确保在给定的 Reduce 分区中,中间 key/value 对是按照 key 值升序处理的。这样的顺序保证对输出的每个文件都是有序的,这样在 Reduce Worker 在读取时非常方便,例如可以对不同的文件使用归并排序。
Combiner Function
在某些情况下,Map 函数产生的中间 key 值的重复数据会占很大的比重(例如词频统计,将产生成千上万的 <the, 1> 记录)。用户可以自定义一个可选的 Combiner 函数,Combiner 函数首先在Map函数中将这些记录进行一次合并,然后将合并的结果再交给Reduce函数。Combiner 函数的代码通常和 Reduce 函数的代码相同,启动这个功能的好处是可以减少通过网络发送到 Reduce 函数的数据量。
跳过损坏的记录
用户程序中的 bug 导致 Map 或者 Reduce 函数在处理某些记录的时候crash。通常会修复 bug 再执行 MapReduce,但是找出 bug 并修复它往往不是一件容易的事情(bug 有可能在第三方库)。与其因为少数坏记录而导致整个执行失败,不如有一个机制可以让损坏的记录被跳过。这在某些情况下是可以接受的,例如在对一个大型数据集进行统计分析时。
Worker 可以记录处理的最后一条记录的序号发送给 Master,当 Master 看到在处理某条记录失败不止一次时,标记这条记录需要被跳过,下次执行时跳过这条记录。
信息统计
Master程序内部可以运行一个Http Server,用于记录MapReduce作业的各个信息,记录下来并展示给用户用于分析。可记录的信息包括但不限于:
- 正在进行中、完成、失败的任务数量
- 任务的完成进度
- 处理、输出的字节数量
- 各任务处理的速率