总结
源代码仓库:OceanPresentChao/HyoukaSocialNetwork
Demo:演示
研究背景
社交网络在维基百科的定义是“由许多节点构成的一种社会结构。节点通常是指个人或组织,而社交网络代表着各种社会关系。”在互联网诞生前,社交网络分析是社会学和人类学重要的研究分支。早期的社交网络的主要指通过合作关系建立起来的职业网络,如科研合作网络、演员合作网络等。
小说、动画、电影等作品为人们创建了一个虚构世界,我们很容易想到在其中也有可能隐含着一个社交网络。对虚构作品的社交网络进行分析有利于我们更好地理解作品,把握作者对作品中的人物与事的关注程度,从量化理性的角度对作品进行分析。
动画、电影等作品由于创作形式本身的特点,包含大量图像、音频,抽象层级高,难以进行信息提取和量化。而小说采用文本的形式,对作品中的人物有较为明确的指代关系,同时现在对文本的分词算法相当成熟,还有类如NLP的对文本进行情感分析的技术,通过计算机对小说等文本作品的分析门槛低,准确率高。
本次实验对日本推理作家米泽穗信2001年创作的小说《冰菓》前四部的社交网络进行了分析研究。
研究方法
文本预处理
获取到小说原文本后首先对其进行文本预处理。去除小说中的章节名称、注释、转义字符串等,保证被处理的文本的纯净度防止对后续的分词操作产生影响。
除此之外我们需要对《冰菓》小说的特点进行总结,便于在研究时采用合适的方法进行分析:
- 《冰菓》是一本日本推理小说
- 《冰菓》采用第一人称描写
- 《冰菓》第三部采用了多视角切换的描写方法
- 《冰菓》约80%的人物只在一部中出现
- 《冰菓》以人物间对话描写为主
小说词典
为了准确地提取出小说中的人物,需要根据小说内容构建小说人物名称词典,对于国内的小说使用python的 HarvestText 直接进行分词能有不错的效果,但《冰菓》是日本的小说,HarvestText 对日本人名的分词准确率较低。具体问题具体分析,制作一个专属的词典提高分词准确率是必要的。
| 折木奉太郎 | 折木供惠 | 福部里志 | 千反田爱瑠 | 伊原摩耶花 | 糸鱼川养川 |
| 关谷纯 | 海藤武雄 | 杉村二郎 | 山西绿 | 入须冬实 | 江波仓子 |
表格 1 《冰菓》中出现的人物(部分)
除了人物正式名称的词典,在小说内同一个人可能会有不同的称呼。比如千反田对折木的称呼是折木同学,而里志对折木的称呼是奉太郎。这点同样需要人工提取出来,生成一个同义词词典。
词典制作完成后使用 Harvesttext 的 add_entities 函数生成实体链接。实体链接给定某些实体及其可能的代称,以及实体对应类型。将其登录到词典中,在分词时优先切分出来,并且以对应类型作为词性,也可以单独获得语料中的所有实体及其位置。
| 福部里志 | 福部里志 | 里志 | 阿福 | 福部同学 | 小福 |
表格 2 《冰菓》中对福部里志的称呼
人物出场次数
分段分句
获得处理后的文本,需要对其进行分段并分句,分段分句工具采用Python的 HarvestText 库,它的分词工具依赖于jieba库,jieba库作为相当知名的中文分词工具之一,具有轻量性和便捷性,其内置了部分词典,也可以使用用户自定义词典,准确率较高。对整体文本进行分句后得到每一部的语句数组。
指代消解
在信息抽取中,由于用户关心的事件和实体间语义关系往往散布于文本的不同位置,其中涉及到的实体通常可以有多种不同的表达方式,为了更准确且没有遗漏地从文本中抽取相关信息,必须要对文本中的指代现象进行消解。
例如:
(1) 李明怕高妈妈一人呆在家里寂寞,他便将家里的电视搬了过来。
(2) 人们都想创造美好的世界留给孩子,这可以理解,但不完全正确。
上面两个例子中的加粗部分,很明显依赖于前文。
在语言学把用于指向的语言单位(上面例子中的粗体部分)称为照应语(或指代语Anaphor),被指向的语言单位(具体的实体)称为先行语(或先行词Antecedent)。而确定照应语所指的先行语的过程就是指代消解。
根据2.1中所提到的小说《冰菓》的特点2和5:采用第一人称描写以及大多是人物间对话的描写。《冰菓》文本的指代消解工作就显得尤为困难。我在实验初期寻找了多个中文NLP库,但结果都很不理想,深感想要精确地使用算法进行指代消解并非我所能及的事。
因此我采用了将“我”均指代为主角“折木奉太郎”,同时忽略人物对话间的代词避免一些不是指代主角的代词“我”被错误识别。根据2.1中提到的特点3,小说第三部采用了多视角的写法,因此需要把4位主要人物各自视角的文本提取出来,再分别修改“我”的指代进行统计。
统计人物出场次数
命名实体识别(英语:Named Entity Recognition),简称NER,是指识别文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等,以及时间、数量、货币、比例数值等文字。
通过遍历2.3.1中获得的语句数组,对每一句进行分词,命名实体识别,将词性为“人名”的词单独提取出来,由于经过了2.2实体链接的处理,同一人物不同的称呼出现啊的次数会被统计在人物的正式名称下。最终可以得到《冰菓》中所有出场人物的出场次数。
人物关联度
利用邻近共现关系。每当一对实体在两句话内同时出现,就可以证明这两个人物间存在关联。同时出现的次数越多,就说明这两者的关联度越高。通过遍历整本小说可以得到所有出场人物间的关联度。
建立社交网络
经过2.3和2.4,获得了每个人物的出场次数和人物之间的关联程度。将每个人物抽象成一个节点,以出场次数为点权,两个人物间的关联程度为边权,可以建立小说《冰菓》的社交网络图。
使用ECharts可视化库将社交网络图绘制如下:
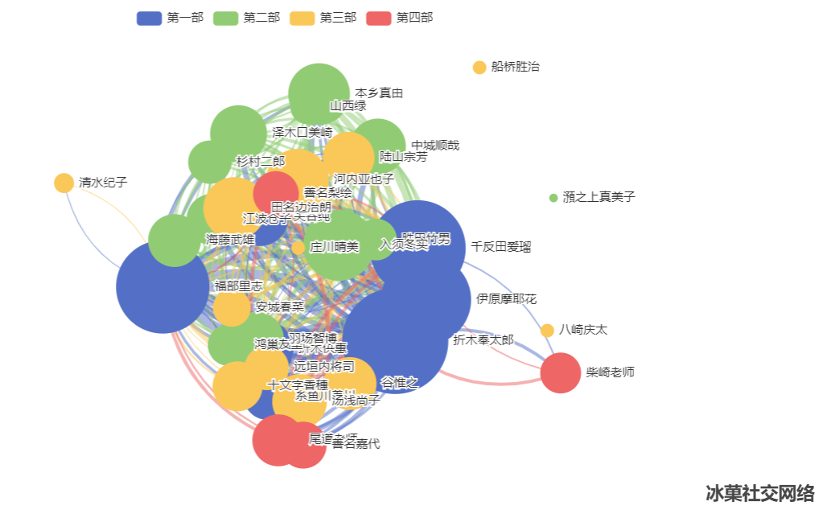
人物中心度
仅仅根据出场次数并不能说明该人物在小说中的重要程度,一个图中的结点重要性不仅依赖于其自身,还依赖于其周边的结点的重要性。使用PageRank算法计算小说中每个人物的重要程度。
PageRank,又称网页排名、谷歌左侧排名,是一种由搜索引擎根据网页之间相互的超链接计算的技术,而作为网页排名的要素之一,以Google公司创办人拉里·佩奇(Larry Page)之姓来命名。Google用它来体现网页的相关性和重要性,在搜索引擎优化操作中是经常被用来评估网页优化的成效因素之一。
假设一个由4个节点组成的群体:A,B,C和D。如果所有节点都只链接至A,那么A的PR(PageRank)值将是B,C及D的Pagerank总和。
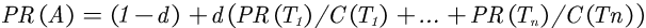
- PR(A) 是节点A的PR值
- PR(Ti)是节点Ti的PR值,在这里,节点Ti是指向A的所有节点中的某个节点
- C(Ti)是节点Ti的出度,也就是Ti指向其他节点的边的个数
- d 为阻尼系数
对2.5中建立的图进行PageRank算法我们可以得到小说中前5重要的人物:
| 排名 | 人物 | PR值 |
|---|---|---|
| 1 | 折木奉太郎 | 179.62393686062052 |
| 2 | 千反田爱瑠 | 89.32020479610543 |
| 3 | 福部里志 | 77.32474777798365 |
| 4 | 伊原摩耶花 | 69.77888275023848 |
| 5 | 入须冬实 | 15.412532393054592 |
评论词云
使用爬虫技术获取B站用户对于2012年动画版《冰菓》近300条评论。使用TextRank算法对评论的关键词进行提取统计得到了B站用户的评论词云,排名前10的关键词为:
| 排名 | 关键词 | 关键度 |
|---|---|---|
| 1 | 好奇 | 22.329069562414 |
| 2 | 旷世 | 19.329461741701945 |
| 3 | 喜欢 | 19.118688789129283 |
| 4 | 推理 | 18.06371347347648 |
| 5 | 蔷薇 | 16.844134740216347 |
| 6 | Doge | 16.563037958295272 |
| 7 | 剧情 | 11.12197441034066 |
| 8 | 好看 | 10.779410462694763 |
| 9 | 美好 | 10.596554981655359 |
| 10 | 青春 | 9.746726518650465 |
总结
本次实验对小说《冰菓》的社交网络进行了分析,统计了小说中人物的出场次数和关联程度,建立了小说中的社交网络,使用PageRank算法计算了每个人物的重要度并对社交媒体上对《冰菓》的评论进行了分析讨论。
实验综合运用了文本处理、图论、爬虫、网页制作等技术,成果有趣,但在内容深度上有待提高,对算法研究程度不够深入。